 Det er så mye som spiller inn om du f.eks. skal si noe om råvarepriser, valutakurser eller etterspørsel eller produkter og tjenester, at det skal veldig mye til å spå rett om fremtiden. Dessuten er det mange sammenhenger mellom ulike variable. De sammenhengene er ofte komplekse og det er slett ikke alltid slik at historiske sammenhenger vil være lik fremtidens sammenhenger.
Det er så mye som spiller inn om du f.eks. skal si noe om råvarepriser, valutakurser eller etterspørsel eller produkter og tjenester, at det skal veldig mye til å spå rett om fremtiden. Dessuten er det mange sammenhenger mellom ulike variable. De sammenhengene er ofte komplekse og det er slett ikke alltid slik at historiske sammenhenger vil være lik fremtidens sammenhenger.
Men like fullt bruker økonomiorganisasjoner over det ganske land og i hele verden, for den del, store ressurser på å lage et budsjett som gir ETT tall med to streker under. De gjør det amerikanerne vil si er å spikre gele til en vegg . Så enkelt er det å finne det eller de tallene som beskriver fremtiden nøyaktig. Det er rett og slett bare flaks om du treffer.
Det jeg snakker om som “spikre gele til veggen”-modeller er det som kalles deterministiske ((The term deterministic indicates that there is no uncertainty associated with a given value or variable; the value is known with certainty)) modeller. Den typen modeller ser bort fra usikkerhet, og antar at fremtiden er mulig å spikre til veggen. Men som det heter i et av de sitatene jeg bruker ofte: Assumption is the mother of all fuckup.
Det innser de som bruker deterministiske modeller også. For å bøte på problemet tyr de gjerne til sensitivitetsanalyser. I slike analyser endrer man gjerne nivået på én variabel, og ser hvordan resultatet ser ut da. Så endrer man en annen, og ser hva resultatet blir da. Og det er gjerne de veldig ekstreme tilfellene man da ser på. Noen har det dertil med å summere opp disse effektene. Det blir som regel veldig feil, med mindre man tror armageddon vil intreffe. Det gjør den sjelden.
En sensitivitetsanalyse er like mye å snekre gele til vegger som tallet med to streker under i budsjettet er det. For det er også bare ett mulig utfall av den variabelen, og den fanger heller ikke opp sammenhengen mellom variablene. For eksempel en så enkel sammenheng som at dersom prisen stiger, faller etterspørselen etter produktet. Og man sier gjerne ikke noe om hvor sannsynlig scenariet er. Er det 40% sannsynlighet? 20%? 5%? 0,2%? Det har man gjerne ikke noen ide om.
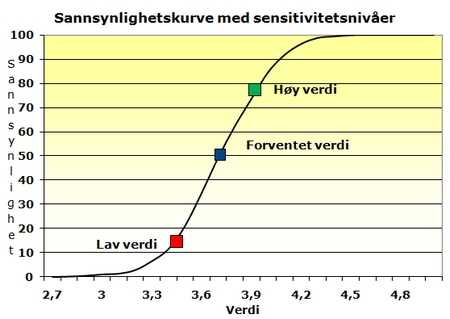
Det jeg jobber med er ikke å snekre gele til vegger. Det er å analysere variablene og sammenhengene mellom dem i en simuleringsmodell, en såkalt Monte Carlo modell ((Monte Carlo sampling refers to the traditional technique for using random or pseudo-random numbers to sample from a probability distribution. The term Monte Carlo was introduced during World War II as a code name for simulation of problems associated with development of the atomic bomb. Today, Monte Carlo techniques are applied to a wide variety of complex problems involving random behaviour. A wide variety of algorithms are available for generating random samples from different types of probability distributions.)) . Hver variabel tilordnes en sannsynlighetskurve. Der sier man gjerne noe om
- Forventet verdi
- Lav verdi med en gitt sannsynlighet (f.eks. 10%)
- Høy verdi med en gitt sannsynlighet (samme som over, dvs. 90%)
Hvordan sannsynlighetskurven ser ut (er den normal, skjev, triangulær etc) kodes også inn i modellen. I tillegg modelleres sammenhengen mellom variablene, enten ved en korrelasjon eller en regresjon. En enkel pris/volum modell vil kunne se slik ut:

Så må man ha et simuleringsverktøy. Det finnes mange. Jeg bruker både en spesialmodell, og en add-on til Excel. Den gjør selve simuleringen. Det gjør den ved å trekke verdier over hele sannsynlighetskurven. Etter tilstrekkelig mange simuleringer vil du få et simulert resultat av pris-volum problemstillingen, som vil gi sannsynligheten for verdien av pris*volum. Slik kan man bygge en stor modell, og resultatet er en
sannsynlighetskurve for et budsjett, et investeringsprosjekt og så videre.

Da kan du si noe om f.eks. sannsynligheten for at du ikke vil generere nok cash til å betale gjelden din. Eller du kan si noe om hvordan risikoprofilen til et prosjekt vil påvirke selskapets verdi. Du kan også si noe om hvor mye risiko virksomheten tåler, gitt nåsituasjonen. Det er egentlig bare fantasien som setter grenser.
Selvsagt er det slik at det er mennesker som setter verdiene i denne modellen også. Kanskje evner ikke de som setter verdiene og bestemmer formen på sannsynlighetskurvene å gjøre det godt nok. Noen ganger intreffer hendelser som vi ikke klarer å forutse. Men det som er sikkert er at en slik modell gir utrolig mye mer informasjon enn gele-tallet noen har forsøkt å spikre fast. og selve prosessen med å jobbe med sannsynlighetskurver og sammenhenger mellom variable, bidrar i seg selv til at man forstår den problemstillingen man forsøker å modellere bedre, er min erfaring.
Når man jobber med risiko, er det viktig å huske at usikkerhet ikke bare innebærer en nedside, men også en oppside. Likevel kan man ikke ta større risiko enn man kan bære, og da er et slikt modellverktøy rett og slett det du trenger. Bruker du bare sensitivitetsanalyser, og dertil kommer på at du skal summere opp risikoen, kan det fort bli slik at du lar gode prosjekter ligge. Rett og slett fordi du ikke har god nok oversikt over risikoen prosjektet innebærer.
Her i Hjørnet er vi selvsagt ikke snauere enn at vi har brukt dette verktøyet før, og i helt andre sammenhenger. Når det gjelder anvendelse av finans og statistikk er det virkelig bare fantasien som setter grenser.
For å oppsummere: Deterministiske modeller mot simuleringsmodeller er som en 2CV mot en Ferrari. Du vet hvem som vinner.